Search plays such an important role on websites. In many cases it is the primary - and sometimes only - approach users will take to find the content they are after. The best-laid plans for site structure, relationships and sitemaps can go out the window for the user who just wants to search. The situation is exacerbated by users being used to superior results from search engines such as Google which can return relevant content across a huge range of resources.
It is important to note that there have been massive advancements in recent years in the areas of search. Search is no longer just about the content.
- User behaviour and wisdom of the crowd can be used to recommend results more relevant to the current user. See Recombee and Algolia.
- Semantic search and knowledge graphs can better capture the essence of a query and relate that to content in the corpus. See LangChain and Pinecone.
- Natural language interfaces and chatbots are an emerging way for users to query content. See Quickchat AI and ChatGPT more generally.
- Conversational interfaces which remember previous queries can build a context of what the user is looking for.
It is important to acknowledge these recent advancements. They will not be explicitly addressed in this article and may indeed be the subject for further articles on search.
This article will explore ways to get the most from the common search technologies in Drupal to return the best results possible, given the technology at hand. To do this we will be using Search API, Solr, content boosting and facets to get the most from the system. Along the way, we will be able to take advantage of structured data, not available to Google, to enhance the search experience.
SearchAPI, Solr and Facets
Search API in conjunction with Solr and Facets has been the go-to solution for search on Drupal for many years. We should also mention that the MySQL backend is an effective alternative for Solr, being able to perform quite well. However, its performance will suffer over larger corpora when used in conjunction with many facets. For this reason, we will be using Solr as a backend for Search API.
Improving your mileage
The solution works quite well in general for many situations. There are however several ways things can be improved to ensure that a site is running as effectively and efficiently as possible. We will now review a few techniques that can be used to get the most from Search in Drupal.
MECE: Cross-cutting dimensions
The “Mutually Exclusive, Collectively Exhaustive” MECE principle is very helpful when planning the site structure which includes content types, taxonomies and the items that appear in them. Generally speaking, for the effective implementation of faceted interfaces, it makes sense to design orthogonal (independent) cross-cutting dimensions to 'slice and dice' your content. Following the MECE approach will ensure that content can be efficiently 'whittled' down as the user selects items from different facets.
As a starting point, we generally will use Type, Topic and Audience for thinking about how our content can be organised. The various content types will have their own requirements and will possibly have their own dimensions which are good candidates for facets.
Index all the full-text content - Paragraphs included
It is vitally important to index every piece of textual content. If the content is available, and a user is likely to search for it, we need to make sure it is in the index. It is possible to index in two ways in Search API: Fields and Rendered Entity. We have found that indexing the rendered entity is superior to fields, because it allows us to include deeper structured content that would otherwise not be indexable by fields.
For example, a complex paragraph may have deeply nested fields. Trying to index this with the fields alone will be a difficult process. The end result is that many fields need to be configured and then joined into full-text queries.
Indexing a “search_index” view mode for content allows all the important things to be indexed. For example:
- Title
- Summary
- Introduction
- Body
- Paragraphs
- Other fields (taxonomies, etc)
When Solr is used, it is possible to index this content as HTML, allowing for boosts for certain elements.
File contents
As much as we would like to take a web-first approach and have all content in an accessible format such as HTML, the reality is that there will be times when attached binary files will be included with the content. A typical example is a “PDF Download” document which contains the full content.
In situations like this, it is possible to use Search API Attachments to index the content. This module relies on a server component that can process the binary file to create text. The initial setup is quite simple, however, it is important to also consider the server resources that may be consumed when using this approach. You will need to review the hosting platform documentation to make sure that only files of a certain size are published. If the files are too large you will get errors in the processing of the index - something which can put a halt to the indexing of your content.
One index to rule them all
Search API supports numerous backends, each of which can support numerous content indexes. It is therefore possible to set up several different indexes based on the requirements. For example, a particular content type may support a special set of indexes that are not available on other content types.
In general, we would recommend against creating multiple indexes if possible. There are several reasons for this:
- Updated content needs to be pushed to multiple indexes which takes time.
- Solr indexes require RAM and duplicating content across then is more intensive.
- Multiple content indexes can be a sign of a poorly conceived content model with low reusability of dimensions across the corpus.
Carefully chosen indexes
A well-designed system utilising MECE, as described above, will efficiently use indexes across the whole corpus. This will encourage more “dense” indexes with more power to discriminate across content of varying types.
Typical indexes include:
- Type
- Topic
- Audience
- Author
When using a single, general purpose content index, it will be necessary to use more sparsely populated indexes:
- Content sub types
Boosting
To this point we have discussed the basics of getting the correct content into the index and having the ability to filter content in efficient ways. The secret sauce of getting the most from the search is to take things a step further and to ensure that content is boosted in strategic ways to deliver relevant content and what is considered important. Below we discuss a number of ways of doing this.
Boosting HTML
HTML content can be indexed into Solr, giving it an advantage over backend like MySQL. This allows for content wrapped in HTML tags to be boosted. For example, H1, H2, H3, B, and STRONG tags all indicate that the textual content is important. It is therefore natural to boost it.
Boosting fields
Sometimes it is helpful to give certain fields an extra boost, especially if the HTML elements are not boosting things sufficiently. For example, a “keywords” field may be in the full index, however, it may be desirable to boost “keywords” or “title” further. In cases such as this, the individual field can be added as a full-text index and boosted as needed. Generally, we would want to avoid this approach as having a single full-text index is simpler, but sometimes it is necessary to tweak in this way.
Boosting Types
Some content types will necessarily be more important than others. For example, an “alert” may have more importance than a run-of-the-mill decision. Search API allows content to be boosted by type. In general, we look to content types that are not being boosted by relevance for this kind of treatment. eg a Section content type may get a slightly higher boost than a mere Page.
Boosting Recency
More recent content will generally be more relevant. Today’s news is better than yesterday's news. It therefore makes sense to boost by date and thankfully Solr provides this capability. Any content that has a date is a candidate for such boosting (article, event, etc). A boosting factor for these types is a powerful way to get more recent content to the top.
Boosting Importance
Editors may decide that some content is more important than others. Why shouldn’t an “editor’s pick” bubble up to the top of search results? In cases like this, an “importance” field can be used to bump content higher in relevance when given a high score by the editor.
Balancing it all out
There is an awful lot of boosting going on. It is important not to get too carried away with the magnitude of boosts and to make sure that they balance out. When designing a search solution we tend to follow these rules of thumb:
- HTML boosts for H1. H2 H3, STRONG and Bold
- Field Title boost of 5
- Field keywords boost of 3
- Date boosts of 1
- Content type (non-date based) boosts up to 1
- Importance boosts up to 1
As usual, your mileage may vary and search must be tested and tuned.
User Experience
The user experience is vital to the success of any search solution. We touch on a few basic principles here.
Facet precedence
Considering a logical order for facets is important for filtering efficiency. Each site will be different, however, we do have the following rules of thumb:
- "Type" will be more discriminatory as they will truly be MECE. Types have the most power and will allow efficient slicing. There will also be generally a fairly small number of them, making them easy to understand. Of course, this is based on the assumption that users are interested in type.
- "Audience" will also likely be a good candidate for a facet. Users will tend to identify with an audience and will therefore be able to unlock easy filtering wins.
- "Topics are helpful for searchers who are motivated by subject area. However, oftentimes the user will already have searched for a keyword which is effectively the topic they are interested in. For this reason, Topic can be less helpful as a filter. They can, however, be very powerful aggregators.
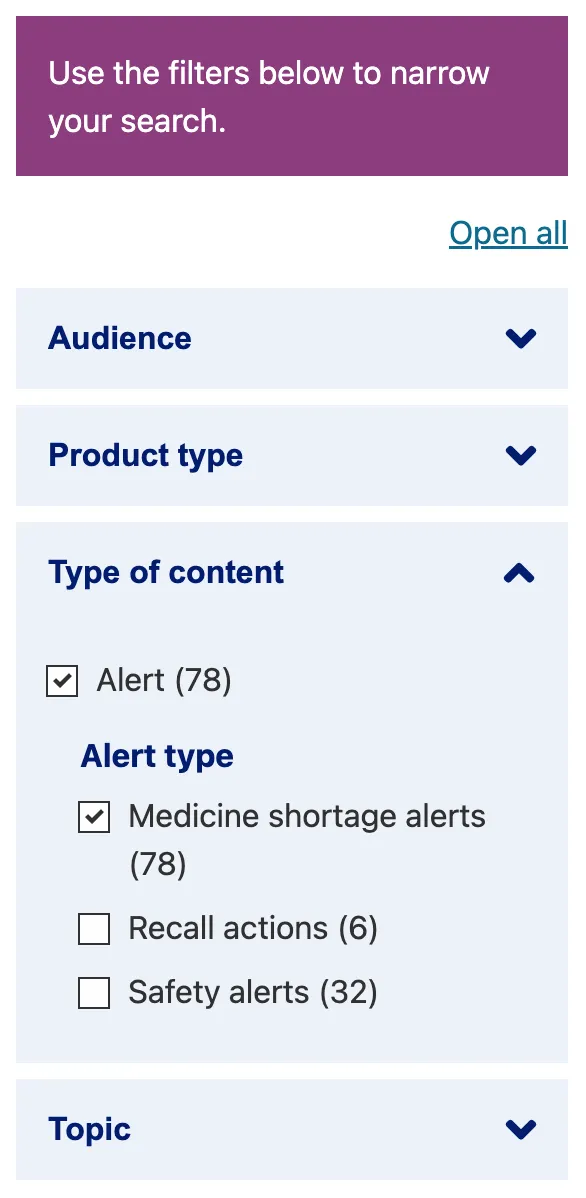
Clean interface
The Facet configuration interface supports many ways of displaying facets. It is worth taking the time to consider how the users will be interacting with the filters. Will they want to select more than one? Is Alpha sorting preferable to Frequency sort? How many need to be seen? Are there any dependent facets based on a selected value? A well-designed system will consider all these things.
Global availability
Finally, as search is generally a global concept, it is important that the search interface is readily available, generally in the top right of the page and additionally in prime position on landing pages as needed.
Testing
The rules are known but the outcomes are not. It is important to validate how the search has been set up.
Integrity
Is this thing on? Is it working? Road test search by:
- Checking that node CRUD operations are reflected in the search results
- Is unpublished content shown?
- Are rare keywords returning the expected results?
- Are results coming back lightning fast?
Generic term testing
The next step is to determine how balanced the search is. For this test, it is a good idea to pick a search term which is very generic and likely to appear across all content types. Typical examples might be “health”, “law”, etc. Run the search and check for the following:
- Are the results as expected as an initial gut instinct?
- Are all content types dispersed as expected?
- Are more recent items coming to the top?
- Are editor picks at the top?
- Are the facets well populated?
If there are problems, further investigation may be needed. To deep dive, create a test View that shows fields for Title, Relevancy and the debug field. This will allow you to peer behind the covers of how Solr is doing things.
Specific term testing
Clients will generally have a few search terms which are important to them. These can be found by reviewing analytics for the most popular terms. A domain expert can determine what would be considered expected or valuable results for these key terms. Choosing a list of three expected items is a good starting point.
It is never going to be possible to always generate the perfect listing (if such a thing exists). It is not possible to pin items in Solr. We are aiming for an acceptable level of quality given the levers we have at our disposal.
If things need to be tweaked, there are a wide range of levers available to us:
- For configuration, we have the various boosting factors available
- For content, the editors can potentially add keywords or other workarounds for getting the right content into the index to help things.
Conclusion
Search is ubiquitous and a popular way to discover content. The bar has been set high for the search experience with users being experienced with highly polished search services on the wider web. Achieving parity or approaching it in Drupal is a difficult task. This article has reviewed several techniques to bring search up to a higher level using the standard site-building techniques in Drupal.
Drupal, and indeed any CMS, has one major advantage over Google and other search engines - The CMS has ready access to the rich set of facets. Search engines typically need to derive this information as it is not available in metadata. A well-designed facet system can therefore offer the user a toolkit not available elsewhere. The secret is in making sure that the results returned are of a high enough quality to keep them from looking elsewhere.
